 超算云
超算云 AI智算云
AI智算云全參數微調DeepSeek滿血版工程開源!
近日,由中國科學院自動化研究所與中科聞歌聯合推出的 DeepSeek-V3/R1 671B 全參數微調開源方案正式發布!這個方案完整開放了從模型訓練到推理部署的全鏈路工程代碼,同步公開實踐驗證過的技術經驗與調優策略,為開發者提供可直接部署的工業化級大模型訓練框架。
01 項目核心特點
1、完整訓練邏輯代碼:基于DeepSeek-V3論文,并結合DeepSeek-V2代碼,該項目實現了包含訓練核心邏輯的modeling_deepseek.py文件,確保與官方架構兼容。
2、高效并行訓練策略:支持數據并行(DeepSpeed ZeRO)與序列并行(SP),在32臺H100服務器集群上完成671B模型的滿血版模型全參數微調。
3、訓練實戰經驗總結:提供多組實驗配置對比(如不同超參數、并行策略選擇下的顯存占用),推薦最優訓練參數,助開發者少走彎路。
02 技術價值解析
技術角度:通過全參數微調,DeepSeek 模型能更好地訓練并擬合目標任務模式和數據分布,整體訓練效果優于 LoRA 等低資源微調方案。
應用角度:針對模型在預訓練階段已具備基礎知識的領域,全參數微調能夠挖掘模型在特定垂直領域(如社會計算、媒體領域等)各種下游任務的性能潛力。
03 快速上手指南
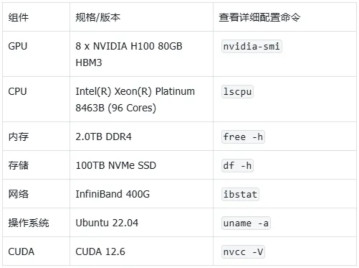
1. 硬件配置
北京超級云計算中心基于H100 GPU集群為該項目構建了高性能計算底座,其技術服務團隊通過深度調優實現了計算環境的適配性優化。單臺服務器配置如下表,集群共有 32 臺相同配置的機器,共享 100TB 存儲空間,掛載路徑為 /nfs。機器操作系統為 Ubuntu 22.04,機器之間使用 IB 網絡進行通信,GPU 之間通過 NVLink 通信,CUDA 版本為 12.6。
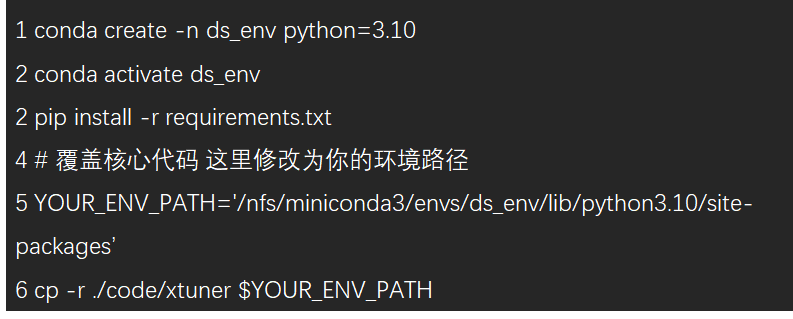
2. 環境配置
本項目基于 xtuner 框架進行擴展和改進,使其支持 Deepseek V3/R1(即 DeepseekV3ForCausalLM 模型架構)的全參數微調,支持數據并行(DeepSpeed ZeRO based DP)和序列并行(Sequence Parallel, SP)。安裝 Python 環境,可根據項目中 requirements.txt 安裝依賴包,并將 ./code/xtuner 與 DeepseekV3ForCausalLM 訓練相關的核心代碼覆蓋原始 xtuner package 的對應代碼即可。
3 .數據準備
該項目基于 OpenAI 標準數據格式進行擴展以兼容 reasoning 數據,每條原始訓練數據格式如下。如果有思考過程,則 assistant 角色的 reasoning_content 字段非空。

為了簡化處理邏輯,該項目將 reasoning_content 和 content 按照 Deepseek 的訓練格式合并到 content 字段中。此外,為了兼容多輪對話的訓練邏輯,還為 assistant 角色的每輪添加了 loss 字段,僅對值為 true 的 content 內容計算 loss。

為了更清晰地展示數據存儲格式,該項目提供了一份轉換后的數據樣例件 ./data/train_example.json 以供參考。在實際訓練時,程序會根據 Deepseek V3/R1 的訓練模版自動轉換為如下格式,這里僅供展示:

4 .啟動訓練
該項目提供了訓練代碼和訓練啟動腳本,其中:
./code/scripts/sft_deepseek.py:sft訓練所需的配置文件,包括超參數設置、model和tokenizer配置、訓練策略等,模型訓練相關的配置均在此文件修改。
./code/scripts/sft_deepseek.sh:sft訓練啟動腳本,該腳本為單個節點的執行文件,因此需要通過 slurm 或 pdsh 在每臺機器執行。對于每臺機器,訓練啟動命令的唯一不同為 NODE_RANK 值,如果共 32 臺機器,則該編號分別從 0 到 31。
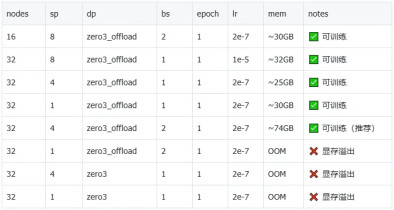
以下是該項目提供的幾組實驗的結論,包括在不同并行策略等配置下模型訓練的可行性。訓練數據 ~100k,訓練上下文長度為 32k。表中報告了每次實驗使用的機器數量(nodes)、序列并行度(sp)、數據并行方式(dp)、單卡 batch size(bs)、迭代輪次(epoch)、學習率(lr)、單卡顯存(mem)、實驗記錄和備注(notes)。
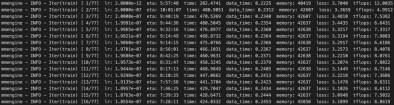
以下是訓練過程中的一個截圖,從 DeepSeek V3 對該項目使用的 reasoning 數據進行全參數微調時,起始 loss 通常在 3.5 左右,經過 1 epoch 訓練后,loss 收斂到 1.2 左右。
5 .模型權重轉換
訓練過程中建議使用至少 100TB 的 SSD 大容量存儲,因為單個 pth 中間結果大約占 7.4TB 硬盤空間。訓練完成后,需要將 pth 轉換為主流推理框架(如vllm等)較好兼容的 huggingface 格式。在單臺機器節點執行 bash ./code/scripts/convert_pth_to_hf.sh 即可完成模型權重格式轉換,可根據實際情況修改腳本中的 pth 路徑和權重保存路徑。
需要注意的是,由于本過程對 CPU 內存有較大需求,因此可以通過虛擬內存進行擴展,防止 Out-of-memory。Swap(交換分區) 是 Linux 的虛擬內存,作用是當物理內存(RAM)不夠用時,把部分數據存入磁盤,釋放 RAM。

6 .模型推理部署
該項目使用 vLLM 對全參數微調后的模型進行簡單部署測試。如果使用 slurm 集群,可參考該項目提供的腳本并執行 sbatch 命令 sbatch ./code/scripts/vllm_deploy_slurm.sh 即可提交作業。半精度(bf16/fp16)模型建議使用4臺機器32卡進行部署,如需配置 ray 或 api server 的端口號,可自行修改 sh 文件。如果需要通過 pdsh 啟動部署(假設使用 node0~node3 四臺機器),可參考以下步驟:
1、設置環境變量(node0~node3)。

2、啟動 Ray Head(node0)。

3、啟動 Ray Worker(node1~node3)。

4、啟動 vLLM(node0)。
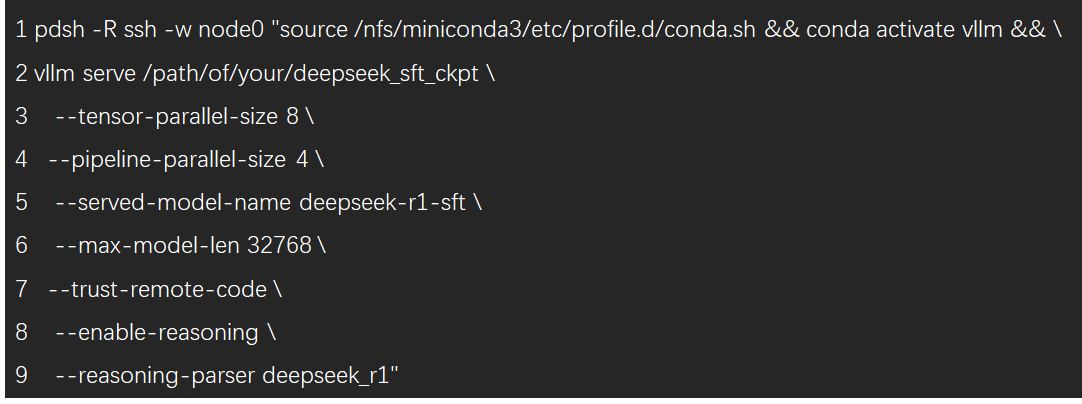
啟動完成后,可通過 curl 命令測試接口是否正常啟動:

稍等片刻后,如果終端輸出符合預期的響應結果,則說明從訓練到部署到整個過程順利完成!??
Github開源地址:
https://github.com/ScienceOne-AI/DeepSeek-671B-SFT-Guide






