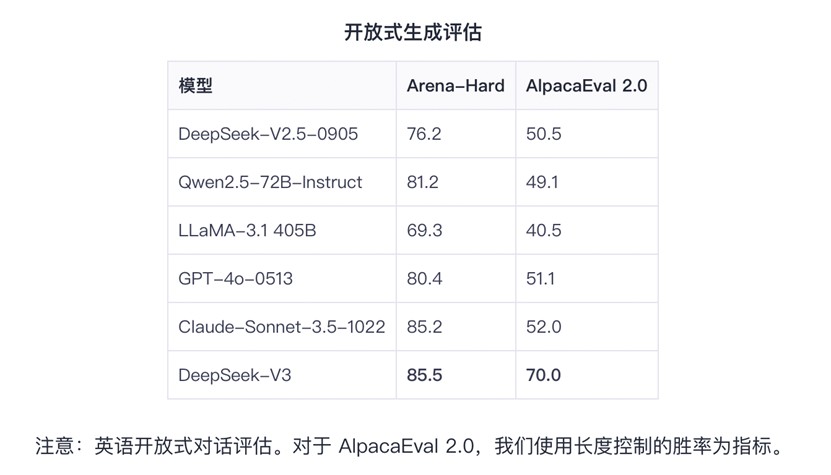
“當硅谷巨頭依賴萬卡集群燒錢訓練時,中國團隊用極低算力成本實現同OpenAI-o1媲美的模型——DeepSeek-R1,以算法突破將訓練成本降至557.6萬美元,登頂全球開源模型榜單。”
原來大模型訓練,本不該如此昂貴。
開發者窘境
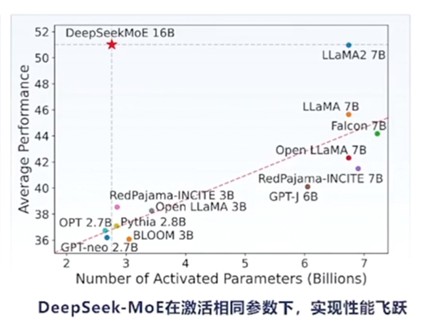
高昂的算力成本如同一道無形的枷鎖,讓許多中小型企業和個人開發者望而卻步。例如,某初創公司曾計劃開發一款圖像識別應用,但面對A100顯卡高昂的租賃費用,不得不放棄原方案。這不僅讓創業團隊步履維艱,也讓創新變得艱難,許多有潛力的項目因成本高昂而被迫擱淺。如何打破這個困局?1、架構手術刀:DeepSeek-V3的混合專家架構(MoE)能夠在不增加計算成本的情況下,擁有龐大的模型容量。 2、數據蒸餾術:DeepSeek-V3以其6710億的參數規模成為當前最大的開源模型,但在實際應用中僅激活370億參數,這大大降低了計算資源需求,提高了資源利用的效率。3、訓練加速引擎:創新雙向流水線設計,將訓練任務劃分為更小的計算塊(chunk),并通過動態調度實現計算與通信重疊,使GPU利用率提升至95%以上,訓練效率翻倍。
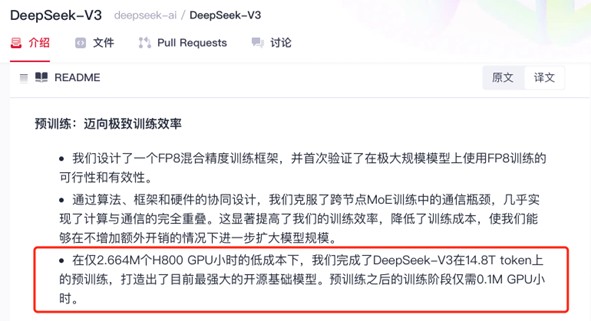
“在僅2.664M個H800 GPU小時的低成本下,我們完成了DeepSeek-V3在14.8T token上的預訓練,打造出了目前最強大的開源基礎模型。預訓練之后的訓練階段僅需0.1M GPU小時。”DeepSeek的成功證明,大模型競賽正在從“暴力美學”轉向“精準外科手術”。
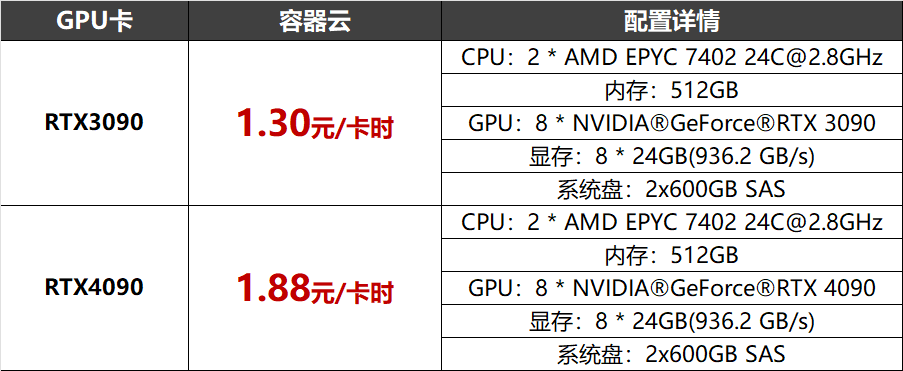
- 極速接入:DeepSeek-R1滿血版(671B)模型已部署至北京超算AI智算云平臺(ai.blsc.cn),支持快速部署,實現開箱即用;- 零配置啟動:內置自動化分布式訓練框架,分鐘級創建預裝DeepSeek的輕量化開發環境,零運維成本啟動;H800/A100/A800/V100、RTX3090/4090、A10/T4,以及國產昇騰910等豐富資源,按需使用,智能調度,空閑資源靈活調用。計算網絡采用1.6Tbps/3.2Tbps IB/RoCE無收斂架構,存儲網絡帶寬達到400Gbps。新注冊用戶:注冊即贈價值200元卡時 3090算力(可完成1億參數模型全量訓練);
企業用戶:RTX 3090/4090最高可享單機8卡一周免費使用(約1344卡時),限云主機、容器云用戶;
**寫在最后**
DeepSeek用一己之力為中國的新一代AI技術開發撕開了一道裂縫,未來已來,北京超算將與中國AI事業一起推動算力成本革命!
 超算云
超算云 AI智算云
AI智算云